
はじめに:雑多な問い合わせをナレッジとして活用するには
FAQやナレッジベースが増えるほど、似た問い合わせが散在しやすくなります。管理コストや検索精度の低下を防ぐには、「本当に似ているFAQ」を自動で見つけ出す仕組みが必要です。
本記事では、TF-IDFというテキスト解析の基本手法とコサイン類似度を組み合わせたプログラムを、Colabで手軽に動かしつつ解説します。金融機関の問い合わせ品質向上にもお役立てください。
1. TF-IDFとは?:文書の特徴語を数値化する仕組み
単純な出現回数では「です」「お客様」などの頻出語に引っ張られ、まったくレアな語だけ注目するとノイズが増えます。
TF-IDFはこのバランスをとり、各文書の“特徴語”を浮き上がらせる手法です。
1.1 買い物カゴでイメージするTFとIDF
- TF(Term Frequency)=“あなたのカゴ”
- その日の買い物で「りんご」が何個入っているか…カゴ内での割合(頻度)が高いほど、その文書内でよく使われる語として扱います。
- IDF(Inverse Document Frequency)=“チェーン店全体の希少度”
- 全国の店舗(全文書)で「トリュフ」がどれくらい売れているか…どこでも売っている「水」は希少度低、限定店舗だけの「トリュフ」は希少度高になります。
- TF×IDF=“特別感”を数値化
- カゴ内の頻出語に希少度を掛け合わせることで、他文書との差を生む“特徴語”に高いスコアを与えます。
1.2 算出の流れと数式
- TF の計算
TF(t,d) = (d文書内の単語tの出現回数) / (d文書内の全単語数) - IDF の計算
IDF(t) = log (全文書数/ 単語tを含む文書数) - TF×IDF の計算
TFIDF(t,d) = TF(t,d) × IDF(t)
1.3 計算例
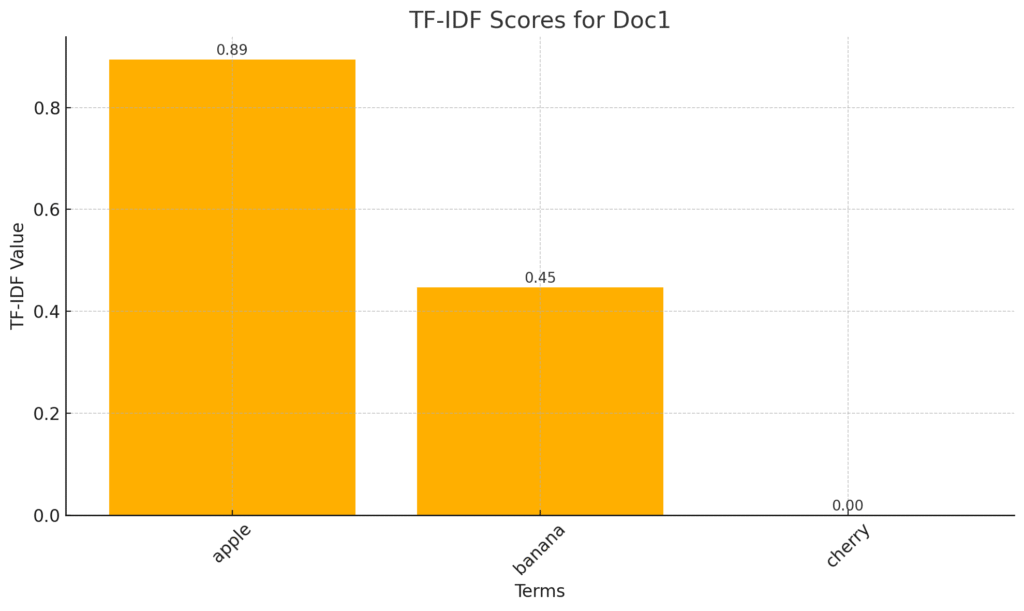
サンプル文書(Doc1: “apple apple banana” / Doc2: “apple banana banana cherry”)のTF-IDFスコアを算出。
| 項目 | 出現頻度 (TF) | 全文書での出現数 (DF) | IDF(スムージングあり) | TF×IDF(未正規化値) | 正規化後(L2ノルム) |
|---|---|---|---|---|---|
| apple | 2/3 ≒ 0.667 | 2/2 | 1.0 | 0.667 | ≒0.90 |
| banana | 1/3 ≒ 0.333 | 2/2 | 1.0 | 0.333 | ≒0.45 |
| cherry | 0 | 1/2 | ≒1.405 | 0 | 0 |
- apple が最も頻出かつ他文書にも出現しますが、スムージングによるIDF=1の掛け算でも高いTF×IDFをキープし、正規化後も最大値になります。
- banana は同じIDFですがTFがappleの半分のため、スコアはその次点。
- cherry はDoc1に未登場なのでスコア0です。
2. 類似検索プログラムの全体像
1. データ準備
外部CSV(id, question, answer)を用意し、「question+answer」をcontent列に結合
2. 前処理
クリーニング関数で不要文字を除去
3. SudachiPyで形態素解析→トークン化
辞書をもとに日本語の文章を“単語”として切り出す
例:「パスワード再設定方法」→ [“パスワード”, “再”, “設定”, “方法”]
tokenizer_obj = dictionary.Dictionary().create()
split_mode = tokenizer_obj.SplitMode.C
def sudachi_analyzer(text: str):
return [m.surface() for m in tokenizer_obj.tokenize(text, split_mode)]4. TF-IDFベクトル化
vectorizer = TfidfVectorizer(tokenizer=sudachi_analyzer, token_pattern=None)
tfidf_matrix = vectorizer.fit_transform(sim_df['content'])5. 類似度計算
コサイン類似度※を使い、閾値以上の上位3件を抽出 ※TF-IDFで得た文書ベクトル同士を比較し、「どれだけ似ているか」を定量化する方法
1.0 に近い:非常に類似 0.0 に近い:ほとんど共通要素なし
nn = NearestNeighbors(n_neighbors=TOP_K+1, metric='cosine', algorithm='brute')
distances, indices = nn.kneighbors(tfidf_matrix)6. 結果出力
各FAQに対し、最も類似度が高いFAQのIDとスコアをCSVで保存
3. サンプルコード(Google Colab実行手順付き)
以下に紹介したプログラムをそのままColabに貼り付けるだけで実行可能です。
# Colab で一度だけ必要なインストール
!pip install --upgrade pip setuptools
!pip install sudachipy sudachidict_core pandas scikit-learn
import os
import re
import pandas as pd
from sudachipy import dictionary
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.neighbors import NearestNeighbors
# --- パラメータ ---
FAQ_CSV_PATH = '/content/faq_data.csv' # サンプルFAQデータ(外部ファイル)
INPUT_SIM_PATH = '/content/faq_for_similarity.csv' # 質問+回答を合成した類似検索用入力
OUTPUT_SIM_PATH = '/content/similarity_output.csv' # 最終出力
SIMILARITY_TH = 0.3
TOP_K = 3
# --- サンプルFAQを別ファイルとして用意(存在しなければ作成) ---
if not os.path.exists(FAQ_CSV_PATH):
faq_list = [
{"id":"000001", "question":"パスワードをリセットするにはどうすればいいですか?", "answer":"ログイン画面の「パスワードをお忘れですか?」をクリックし、メールの指示に従ってください。"},
{"id":"000002", "question":"パスワードを忘れました。どうすれば再設定できますか?", "answer":"ログイン画面の再設定リンクから登録メールを確認して新しいパスワードを設定してください。"},
{"id":"000003", "question":"配送が遅れています。注文はどこにありますか?", "answer":"マイページの追跡番号をご確認ください。運送会社の都合で遅延することがあります。"},
{"id":"000004", "question":"まだ荷物が届きません。なぜですか?", "answer":"配送の遅延が発生している場合があります。追跡情報を再確認し、5日以上遅れていればサポートへご連絡ください。"},
{"id":"000005", "question":"登録しているメールアドレスを変更したいです。", "answer":"アカウント設定からメールを選び、新しいアドレスを入力後、確認メールのリンクをクリックしてください。"},
{"id":"000006", "question":"アカウントのメールを更新できますか?", "answer":"はい。設定のメール更新から手続きを行い、認証を完了させてください。"},
{"id":"000007", "question":"注文をキャンセルできますか?", "answer":"注文後2時間以内であれば、注文履歴からキャンセル可能です。"},
{"id":"000008", "question":"さっきした注文を取り消したいのですがどうしたら?", "answer":"マイオーダーから該当の注文を選び、2時間以内であればキャンセルボタンが表示されます。"},
{"id":"000009", "question":"返品ポリシーを教えてください。", "answer":"商品到着後30日以内で、未使用かつ元の梱包状態であれば返品を受け付けます。"},
{"id":"000010", "question":"30日過ぎた商品は返品できますか?", "answer":"通常の返品は30日以内ですが、例外的にサポート対応が可能な場合があります。お問い合わせください。"},
{"id":"000011", "question":"返金はどうやって受け取れますか?", "answer":"注文ページから返品手続きを開始してください。商品を受領・検査後、返金処理されます。"},
{"id":"000012", "question":"返金はどのくらいで戻ってきますか?", "answer":"返品受領後5~7営業日でお支払い方法に応じて返金されます。"},
{"id":"000013", "question":"インストールの技術サポートはありますか?", "answer":"はい。営業時間内にチャットか電話で無料のインストール支援を提供しています。"},
{"id":"000014", "question":"ソフトのインストールを手伝ってほしいです。", "answer":"サポートチケットを開くかライブチャットをご利用ください。技術担当がステップごとに案内します。"},
{"id":"000015", "question":"請求情報を更新するには?", "answer":"請求設定に移動し、支払い方法を編集して保存してください。"},
{"id":"000016", "question":"登録カードを変更できますか?", "answer":"請求設定のカード情報を更新し、変更を確定してください。"},
{"id":"000017", "question":"アカウントがロックされました。解除方法は?", "answer":"メールに送られた解除リンクを使うか、本人確認のうえサポートに連絡してください。"},
{"id":"000018", "question":"なぜアカウントが停止されているのですか?", "answer":"ポリシー違反が原因の可能性があります。詳細はメールをご確認いただき、不服申し立てはサポートへ。"},
{"id":"000019", "question":"カスタマーサービスの電話番号は?", "answer":"平日9時~18時に 0120-000-000 へお電話ください。"},
{"id":"000020", "question":"サポートの受付時間を教えてください。", "answer":"サポートは月~金の9時から18時まで対応しています。"},
]
faq_df = pd.DataFrame(faq_list)
faq_df.to_csv(FAQ_CSV_PATH, index=False, encoding='utf-8-sig')
else:
faq_df = pd.read_csv(FAQ_CSV_PATH, dtype={'id': str})
# --- 1. 類似検索用データ成形: 検索用のquestion+answer を作成し content に ---
sim_df = pd.DataFrame({
'id': faq_df['id'],
'question': faq_df['question'],
'answer': faq_df['answer'],
'content': faq_df['question'].str.strip() + ' ' + faq_df['answer'].str.strip()
})
# --- 2. 前処理 ※必要に応じて追加(今回は何もなし) ---
def clean_text_simple(text: str) -> str:
text = str(text)
return text
sim_df['content'] = sim_df['content'].apply(clean_text_simple)
# --- 3. SudachiPy 初期化 ---
tokenizer_obj = dictionary.Dictionary().create()
split_mode = tokenizer_obj.SplitMode.C
def sudachi_analyzer(text: str):
return [m.surface() for m in tokenizer_obj.tokenize(text, split_mode)]
# --- 4. TF-IDF ベクトル化 ---
vectorizer = TfidfVectorizer(tokenizer=sudachi_analyzer, token_pattern=None)
tfidf_matrix = vectorizer.fit_transform(sim_df['content'])
# --- 5. 類似度検索 ---
nn = NearestNeighbors(n_neighbors=TOP_K+1, metric='cosine', algorithm='brute')
nn.fit(tfidf_matrix)
distances, indices = nn.kneighbors(tfidf_matrix)
# --- 6. 出力作成---
records = []
for i, (dists, neighs) in enumerate(zip(distances, indices)):
base = sim_df.iloc[i]
rec = {
'source_id': base['id'],
'source_question': base['question'],
'source_answer': base['answer'],
'similarity_1_score': ''
}
similar_count = 0
for dist, j in zip(dists, neighs):
if j == i:
continue
sim = 1 - dist
if sim < SIMILARITY_TH:
continue
similar_count += 1
if similar_count == 1:
rec['similarity_1_score'] = round(sim, 4) # 1位のスコアを4列目に
rec[f'similar_{similar_count}_id'] = sim_df.iloc[j]['id']
rec[f'similar_{similar_count}_question'] = sim_df.iloc[j]['question']
rec[f'similar_{similar_count}_answer'] = sim_df.iloc[j]['answer']
if similar_count >= TOP_K:
break
for k in range(similar_count+1, TOP_K+1):
rec[f'similar_{k}_id'] = ''
rec[f'similar_{k}_question'] = ''
rec[f'similar_{k}_answer'] = ''
records.append(rec)
out_df = pd.DataFrame(records)
# --- 7. 保存 ---
out_df.to_csv(OUTPUT_SIM_PATH, index=False, encoding='utf-8-sig')
print(f"出力ファイル: {OUTPUT_SIM_PATH}")Google Colabでのサンプルコード実行手順
1. 「Google Colab」と検索
2. ノートブックを開くと表示されたらノートブックを新規作成を選択
3. ノートブックにGoogleDriveをマウント
4. サンプルコードを貼り付け
5. 全てのセルを実行(エラーが出た場合も再度実行すれば回ります)
6. 「出力ファイル: /content/similarity_output.csv」と表示されたら成功です。ファイルの部分にFAQファイルと出力ファイルが表示されます。
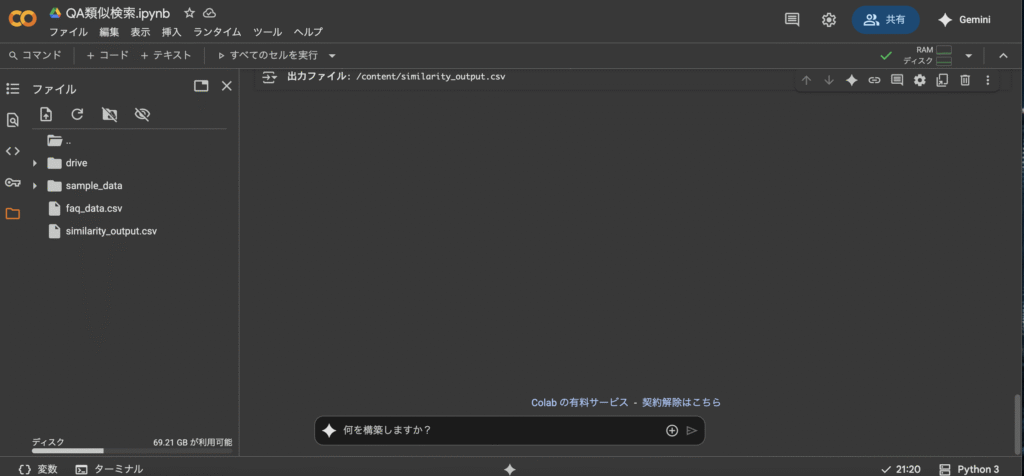
- あとは前処理や入力ファイルなど自分のユースケースに当てはめて試してみましょう。
4. 金融業界での活用ポイント
- FAQ統合・整理
- 類似FAQを自動検出し、文書の重複を削減することで管理コストを軽減
- 応答の迅速化
- 類似事例を即座に抽出し、対応開始までの時間を短縮
- 生成AIのRAG参照データ管理
- 類似度が高いナレッジを重複削除、統合することでRAGの品質向上・維持
5. まとめ
TF-IDFとコサイン類似度を組み合わせることで、
- 文書の特徴語を可視化し、
- FAQ間の「似ている度」を高精度に算出できます。
- まずはサンプルコードを試し、自社FAQでの効果を検証してみましょう。
言語処理についてもっと体系的に学びたい時はこちらの本がおすすめです。
Kindle版

単行本版

Hiro|データサイエンティスト
ベンダーと金融現場の“両サイド視点”でデータ活用を支援中
X(旧Twitter)→ @Hiro_data_fin


コメント